Heterogeneous Demand
UCSD MGT 100 Week 06
Let’s reflect

![]()
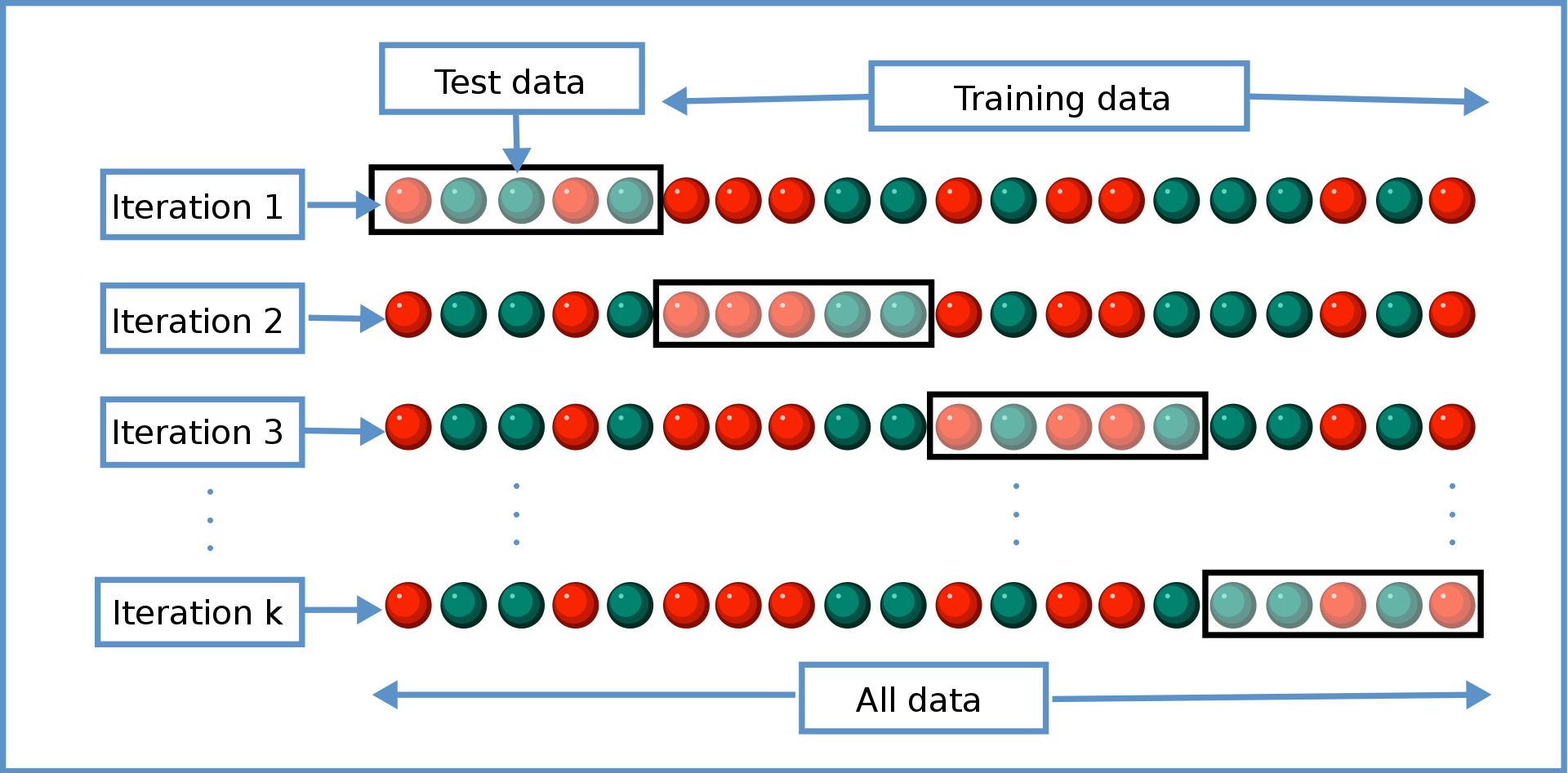
- You estimate the model K times
- Each estimation uses a different (K-1)/K proportion of the data
- We evaluate retrodiction quality K times, then average them
- When K=N, we call that "leave-one-out" cross-validation
- Important: cross-validation is just one tool in the toolbox
- Final model selection also depends on theory, objectives, other criteriaEx-post evaluations
- Can a model withstand changes in the environment?
- Non-random holdouts are strong tests, but can only be retrospective


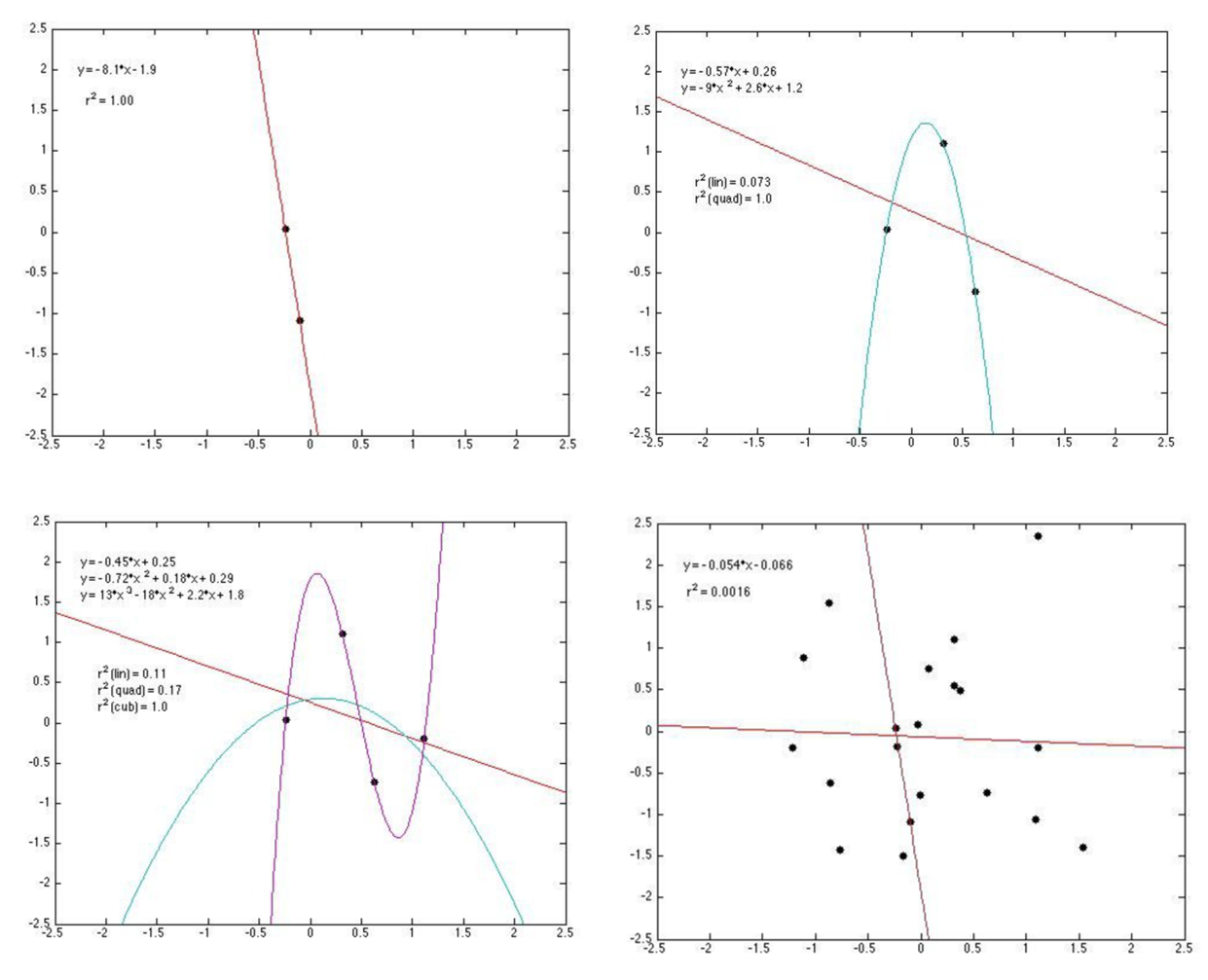
- T/F: Adding random predictors into \(X\) can decrease OLS \(R^2\).
Class script
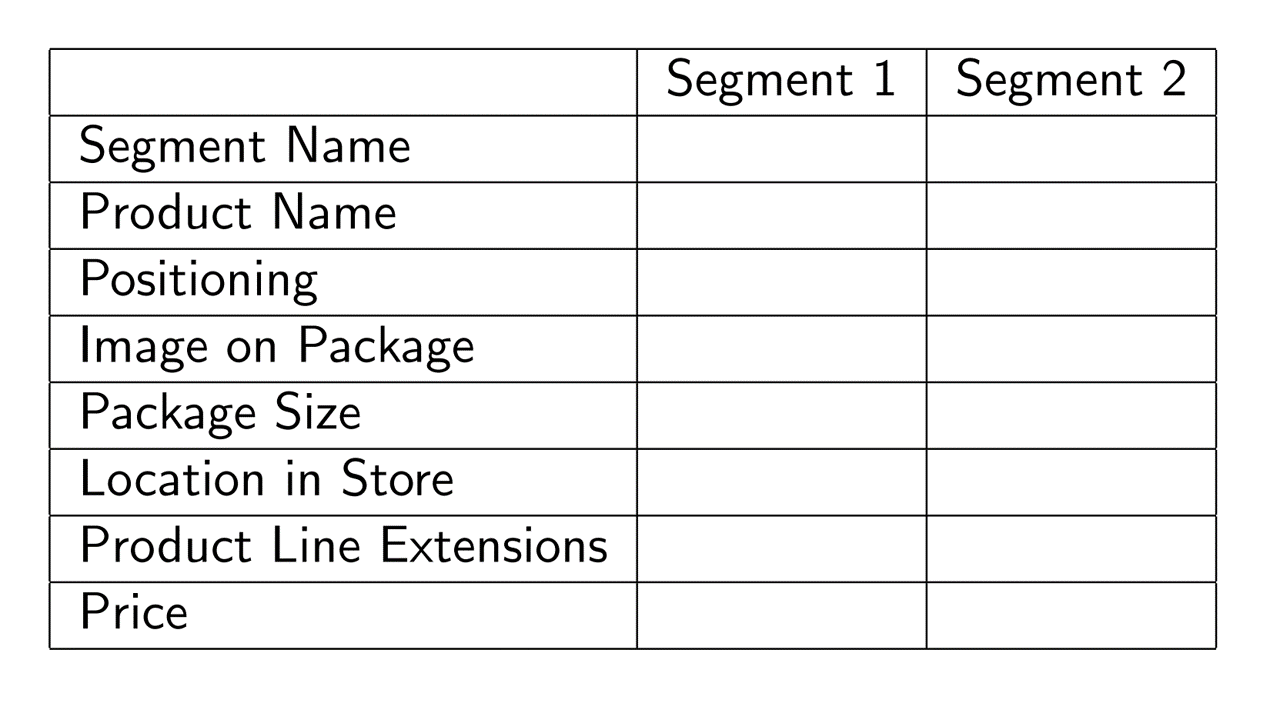
- Add heterogeneity to MNL model
- Individual-level heterogeneity via price-minutes interaction
- Segment-level heterogeneity via segment-attribute interactions
- Both
Homework
- Let’s take a look

Recap
Heterogeneous demand models enable personalized and segment-specific policy experiments
Demand models can incorporate discrete, continuous and/or individual-level heterogeneity structures
Heterogeneous models fit better, but will predict worse if overfit

Going further
