Demand Modeling
MGT 100 Week 3
This version: May 2026 | License: CC BY 4.0 | We use javascript to track readership.
We welcome reuse with attribution. Please share widely.
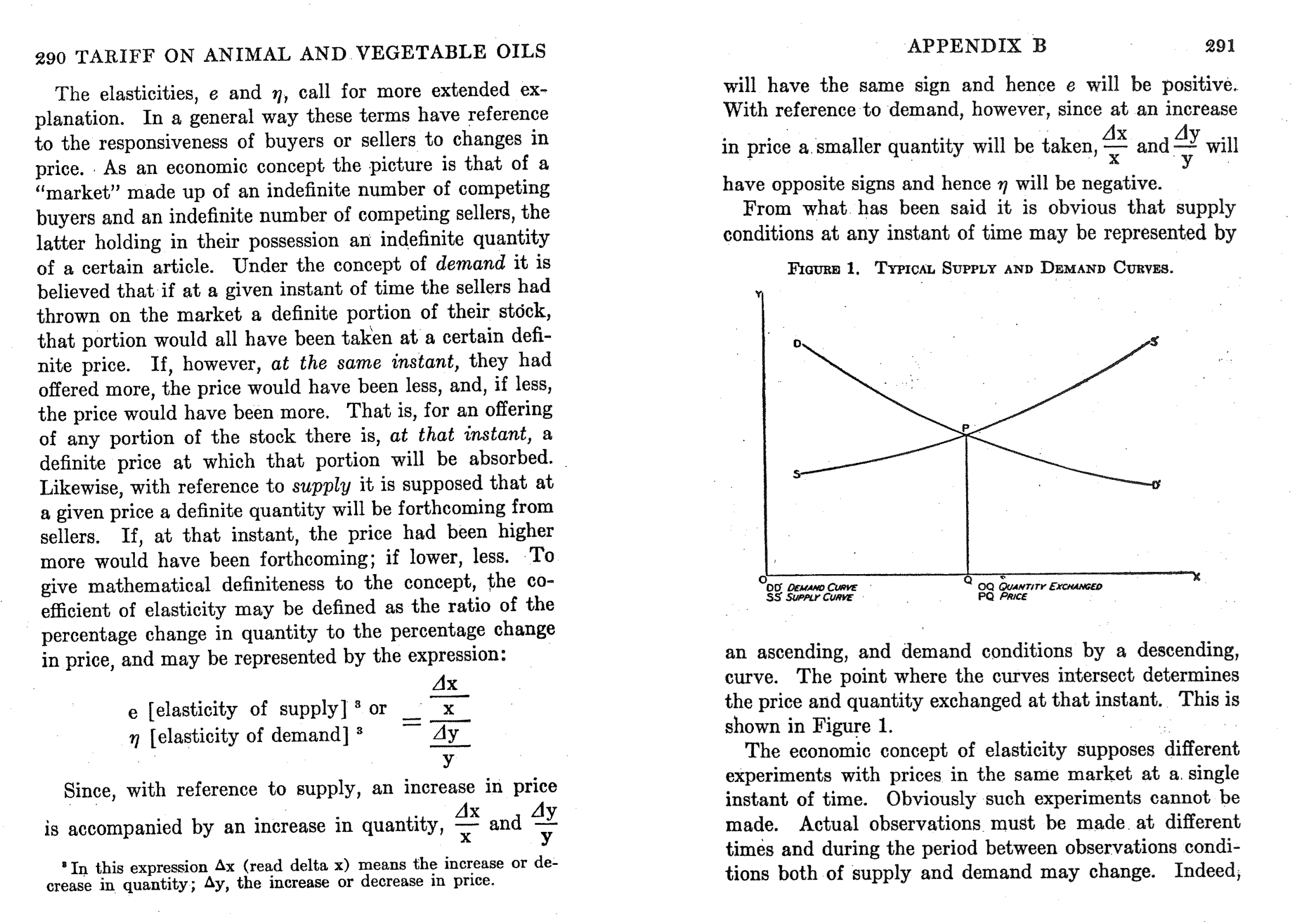
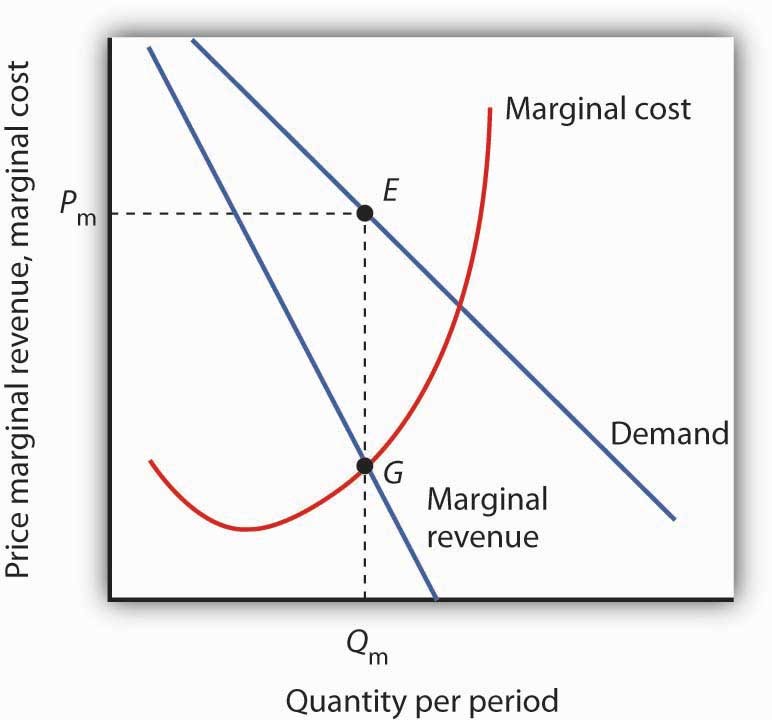
Demand Curve
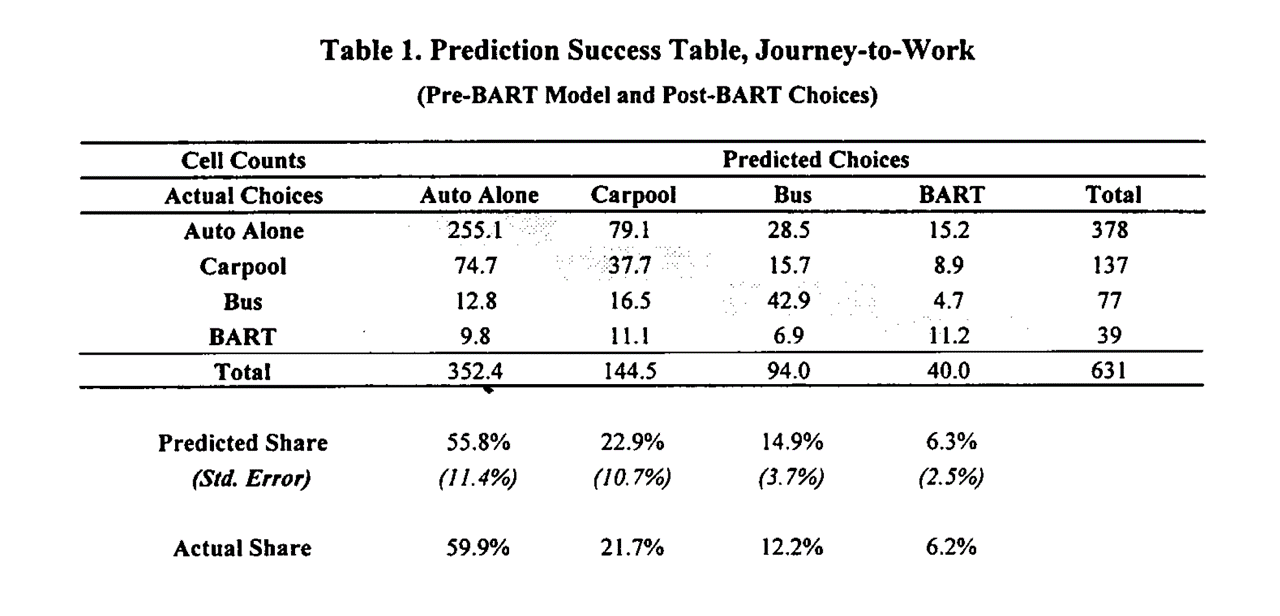
Daniel McFadden & BART

- Economist working at UC Berkeley to empiricize theoretical models of individual choice
- In the early 1970s, funded by NSF to predict how BART would change transit in San Francisco
- Collected pre-BART transportation choices by surveying commuters in neighborhoods slated for BART stations
- Product attributes: walking distance, waiting time, financial cost, automotive preference
- Estimated MNL on pre-BART survey data, then predicted post-BART transit choices
Multinomial Logit (MNL)
IIA: Deeper dive
- Famous example from McFadden (1974): Suppose you estimate demand for transportation with three options: {Blue Bus, Red Bus, Car}, each with 33% market share, and you include product intercepts in utility
- Now suppose you evaluate a counterfactual in which you paint all of the red buses blue, and then you predict market shares in the new choice set {Blue Bus, Car}
- MNL will predict Blue Bus and Car shares of 50%, not 67% and 33%
- Why? MNL infers \(V_{jt}\) based on market shares, so equal market shares imply equal \(V_{jt}\)

MNL in Practice: Alibaba
- Alibaba recommends 6 personalized products, chosen from thousands, on homepage to maximize sales revenue
- Previously: ML algorithm predicted each product’s purchase probability independently, then displayed the 6 with highest expected revenue
- Feldman et al. (2022) proposed using MNL instead, because MNL captures substitution across products — if two displayed products are similar, they cannibalize each other’s demand rather than generating new sales
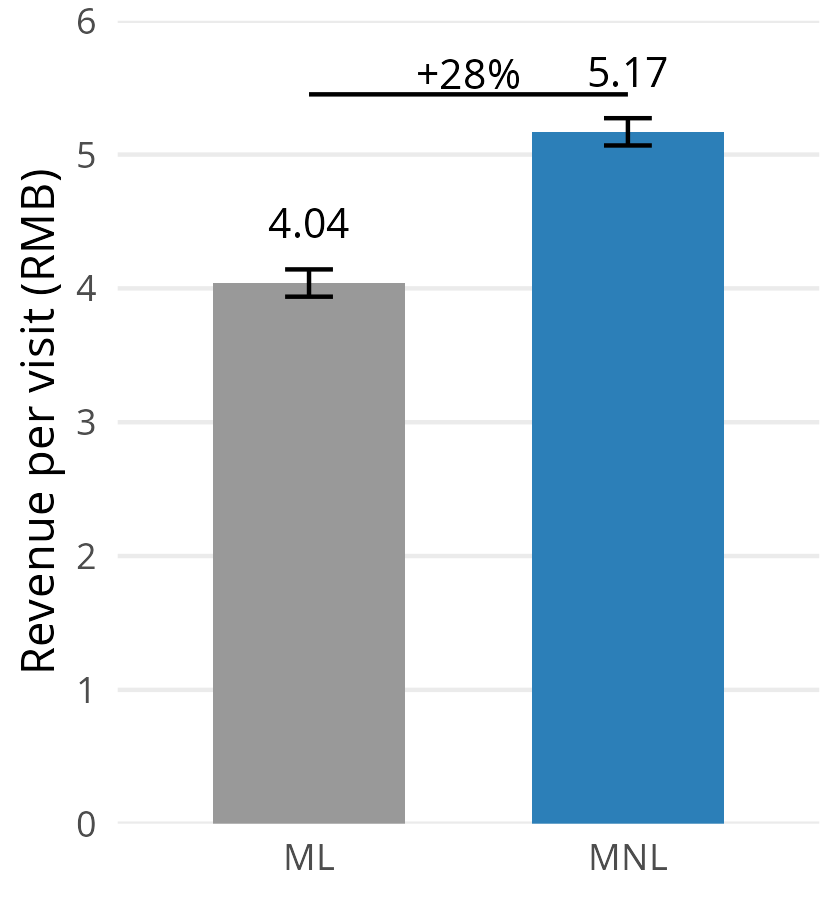
- Field experiment with 5M+ customers on Tmall/Taobao: ML predicted purchase probabilities more accurately, but MNL generated 28% more revenue per visit
- Why? ML ignores substitution and may waste display slots on similar products. MNL’s \(s_{jt}\) formula links all products through the denominator, so it selects more diverse assortments
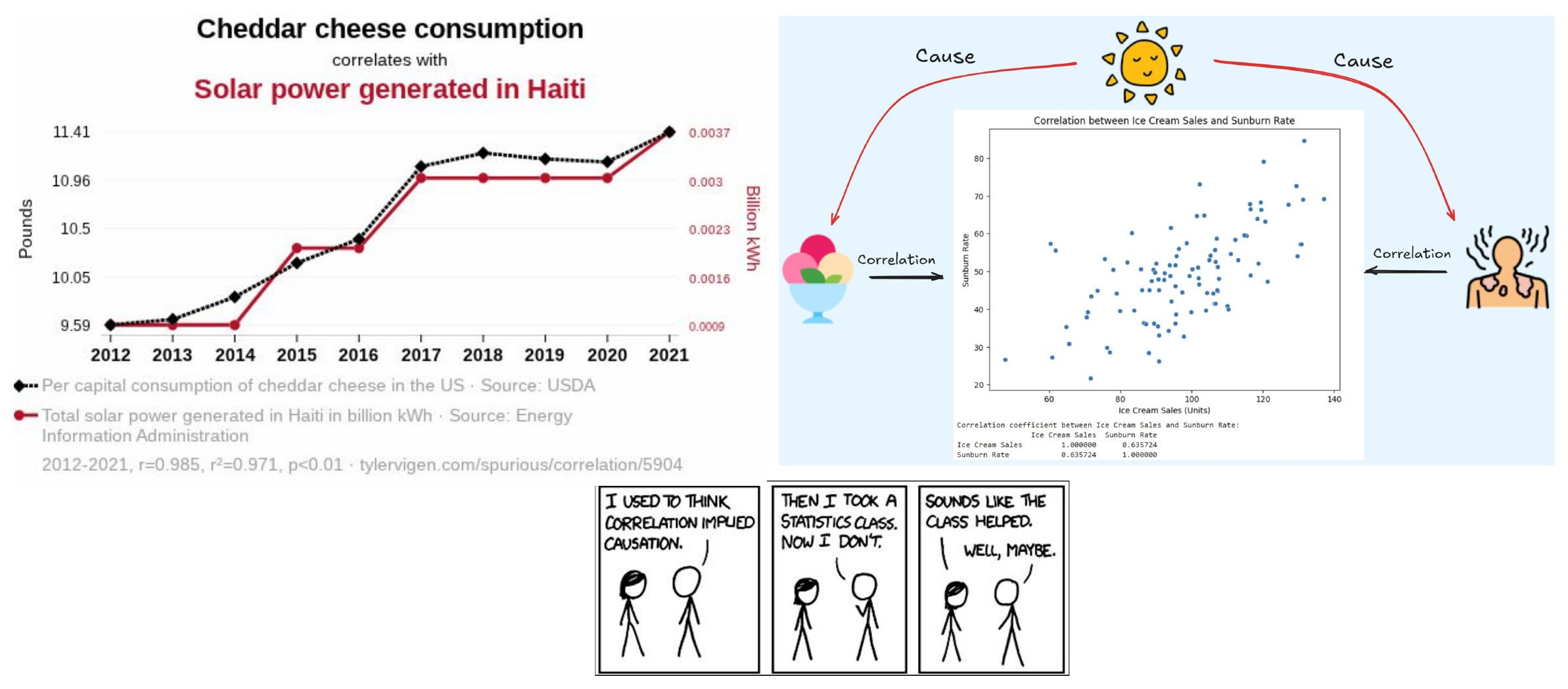
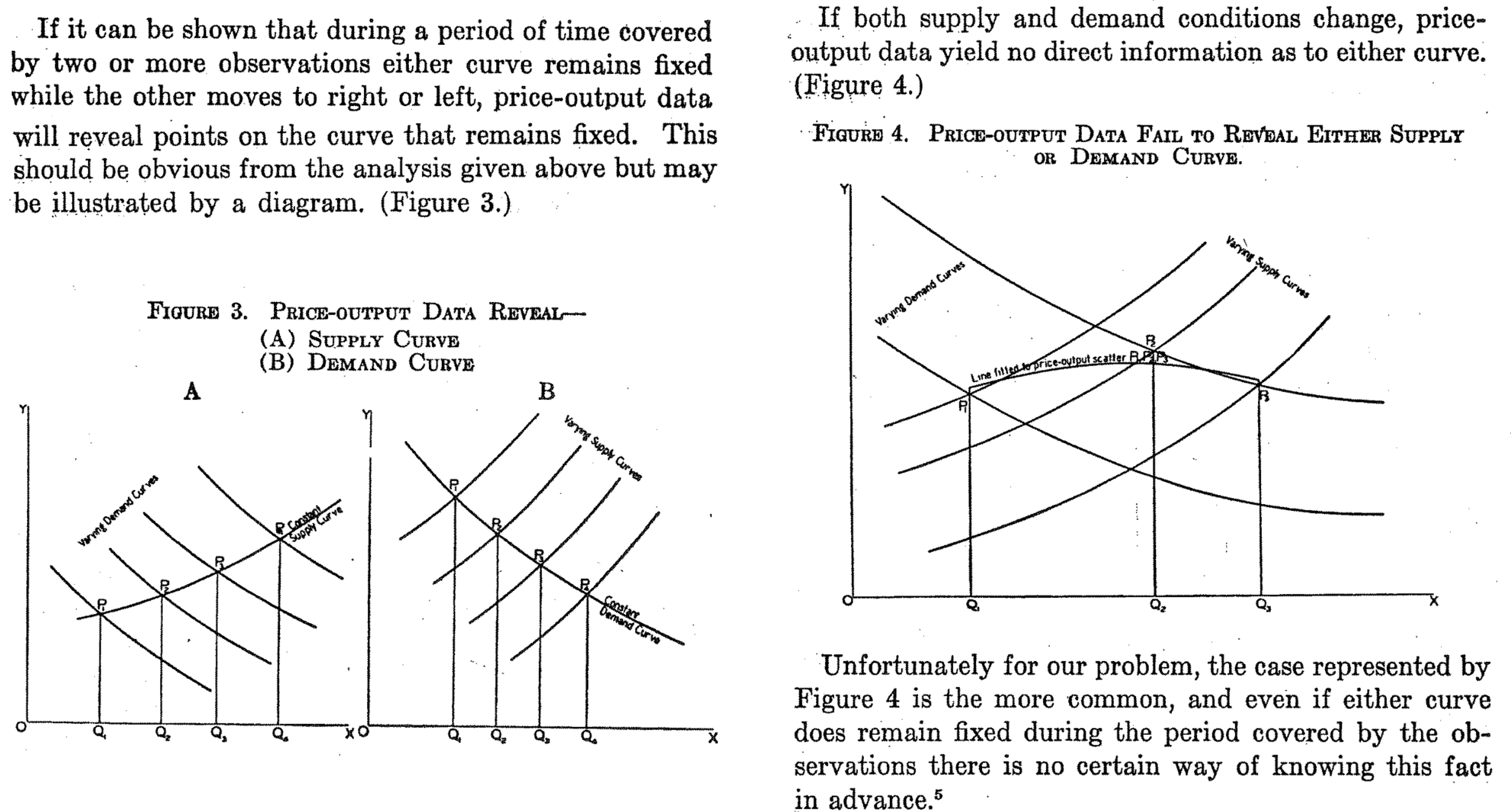
Classic Identification Argument
4. An Analogy
- Foot size significantly predicts reading comprehension among children!
- In fact, age causes foot size and age causes reading comprehension
- Also, crib purchases significantly predict childbirth!

5. Sports example
- Suppose you observe daily sports team ticket prices and sales before and after the team acquires a very popular player
- Prices and sales are both higher after the trade
- Does this mean that higher price caused higher sales?

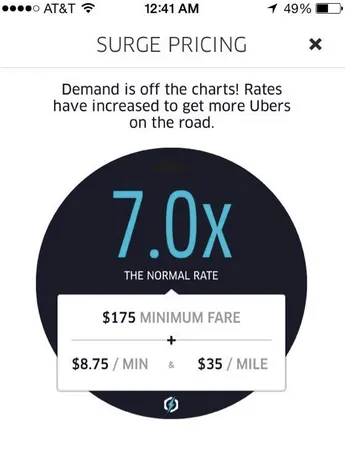
6. Example: Digital systems
- Uber surge pricing:
Positive Demand shocks increase price
Negative Supply shocks increase price - System adjusts the price without knowing the causes
- Many digital inventory-based pricing systems are similar
7. Shrinkflation

- Shrink the package, maintain the price
- Also, “Skimpflation” : reduce ingredient intensity
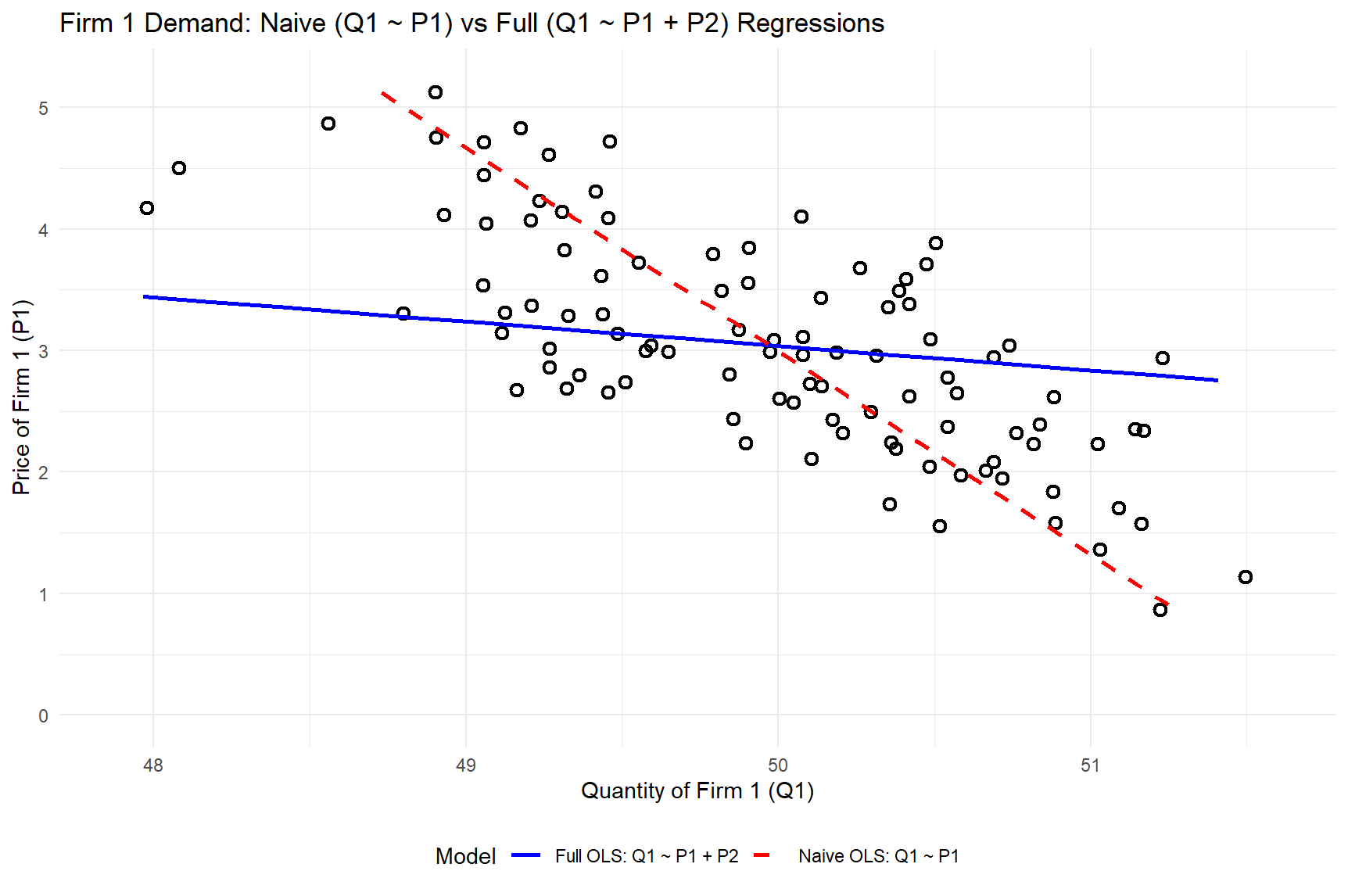
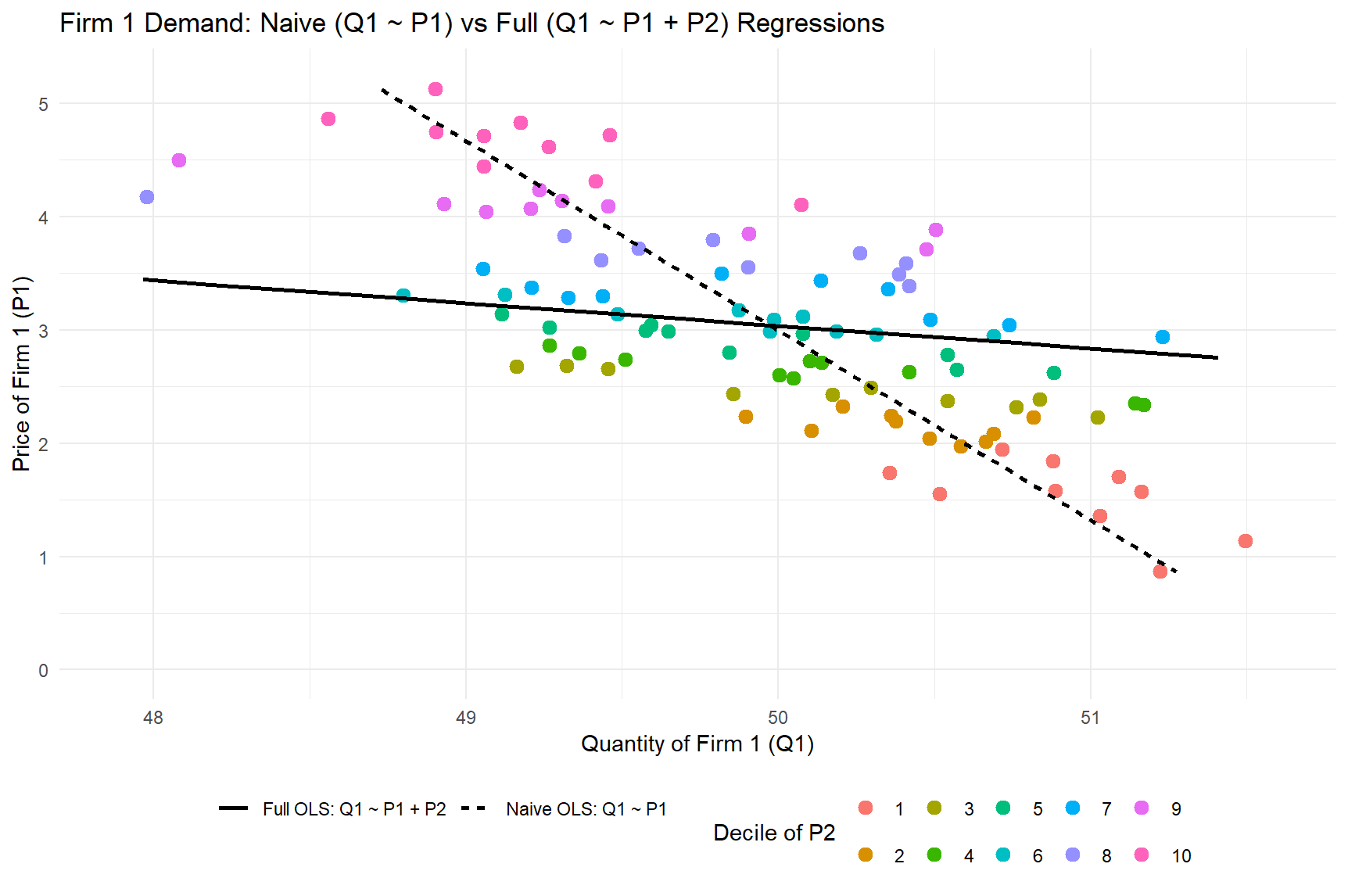

- Describe price endogeneity in your own words
- Generate a novel example related to price and demand
- If time, explain how you might resolve it
Class script
- Wrangle data
- Estimate MNL
- Interpret parameters and SEs
- Assess model fit
Competition
- Estimate MNL with phone dummies and price on each of the 3 cohorts separately
- Create a visualization showing how the price sensitivity parameter has changed across the 3 years

Recap
- Demand modeling enables data-driven sales predictions for counterfactual prices and attributes, facilitating profit maximization
- MNL is popular bc it is powerful, microfounded and tractable
- MNL has limitations (eg, IIA), but is extensible by modeling heterogeneity
- Price endogeneity is a “data problem” that biases demand parameter estimates when price is correlated with unobserved demand shifters. Usually resolved with exogenous price variation

Going further
- Supply, Demand, and the Instrumental Variable: Lessons for Data Scientists from the Economist’s Toolbox
- Causal inference in economics and marketing (Varian 2016)
- Discrete Choice Analysis with R
- Microeconometric models of consumer demand by Dube (2018)
- Empirical Models of Demand and Supply in Differentiated Products Industries by Gandhi & Nevo
