Pricing
MGT 100 Week 6
This version: May 2026 | License: CC BY 4.0 | We use javascript to track readership.
We welcome reuse with attribution. Please share widely.

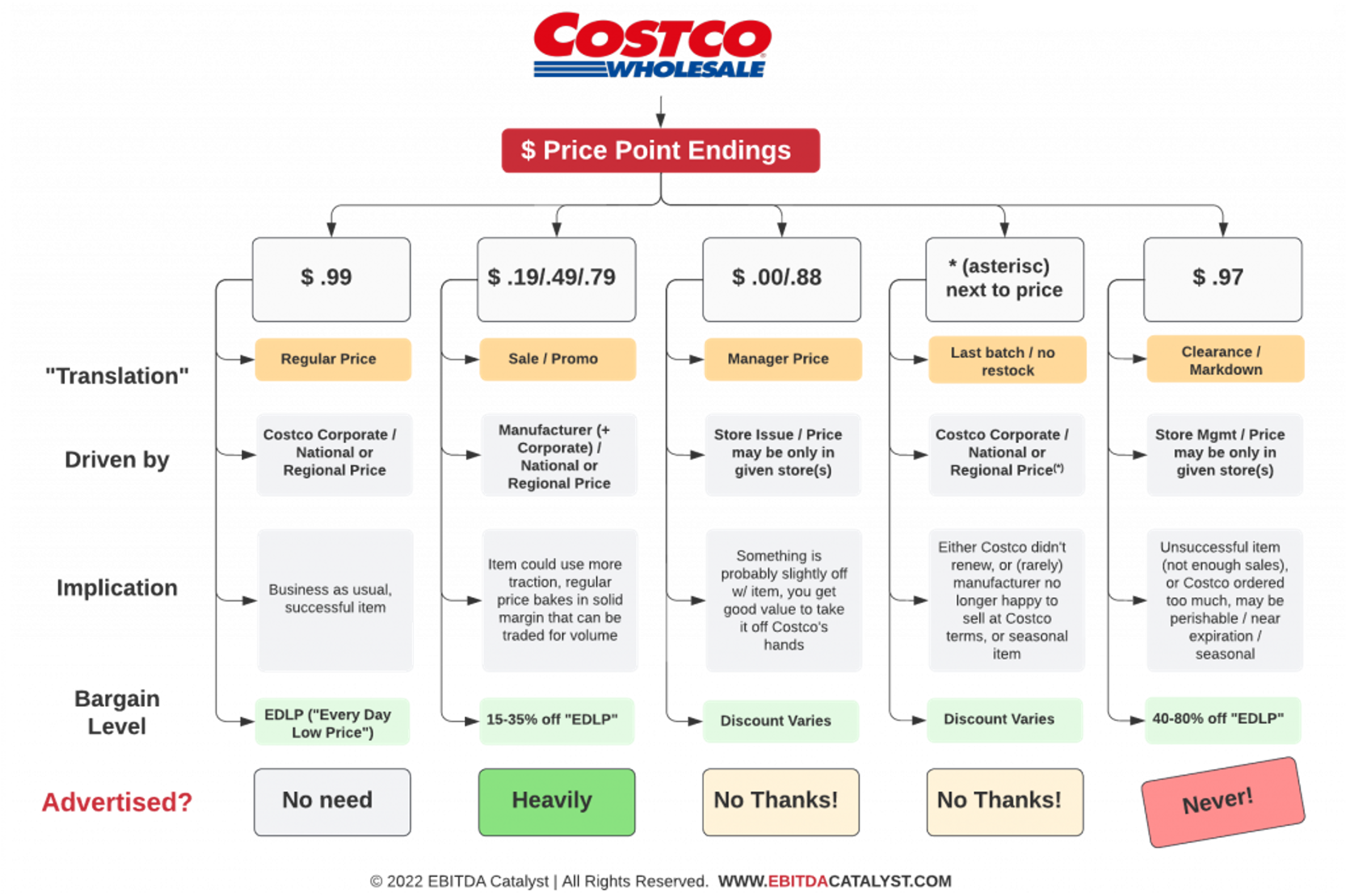
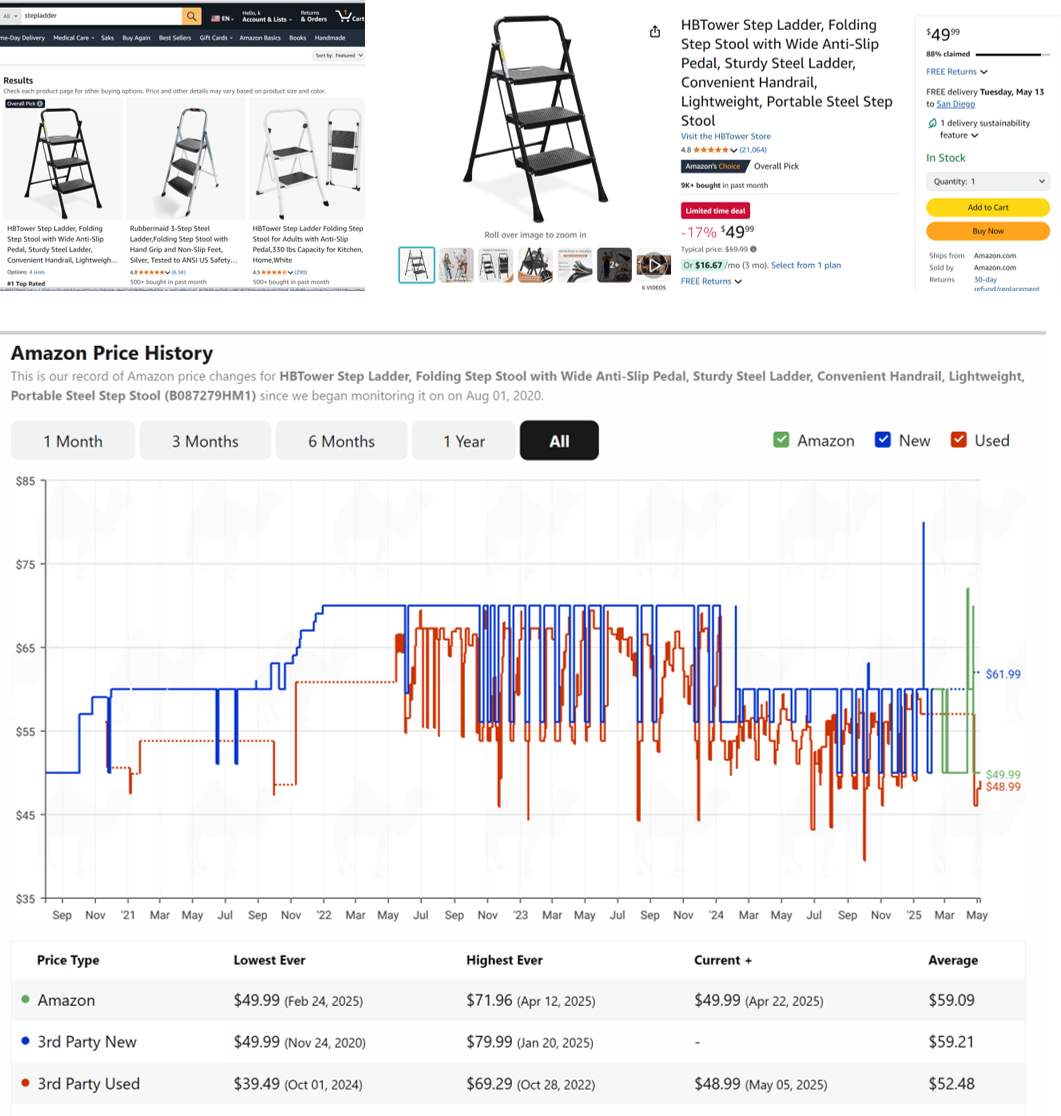
camelcamelcamel | See also PriceSpy, SmartScout; but not Honey or Keepa
Price Changes Are Risky & Scary

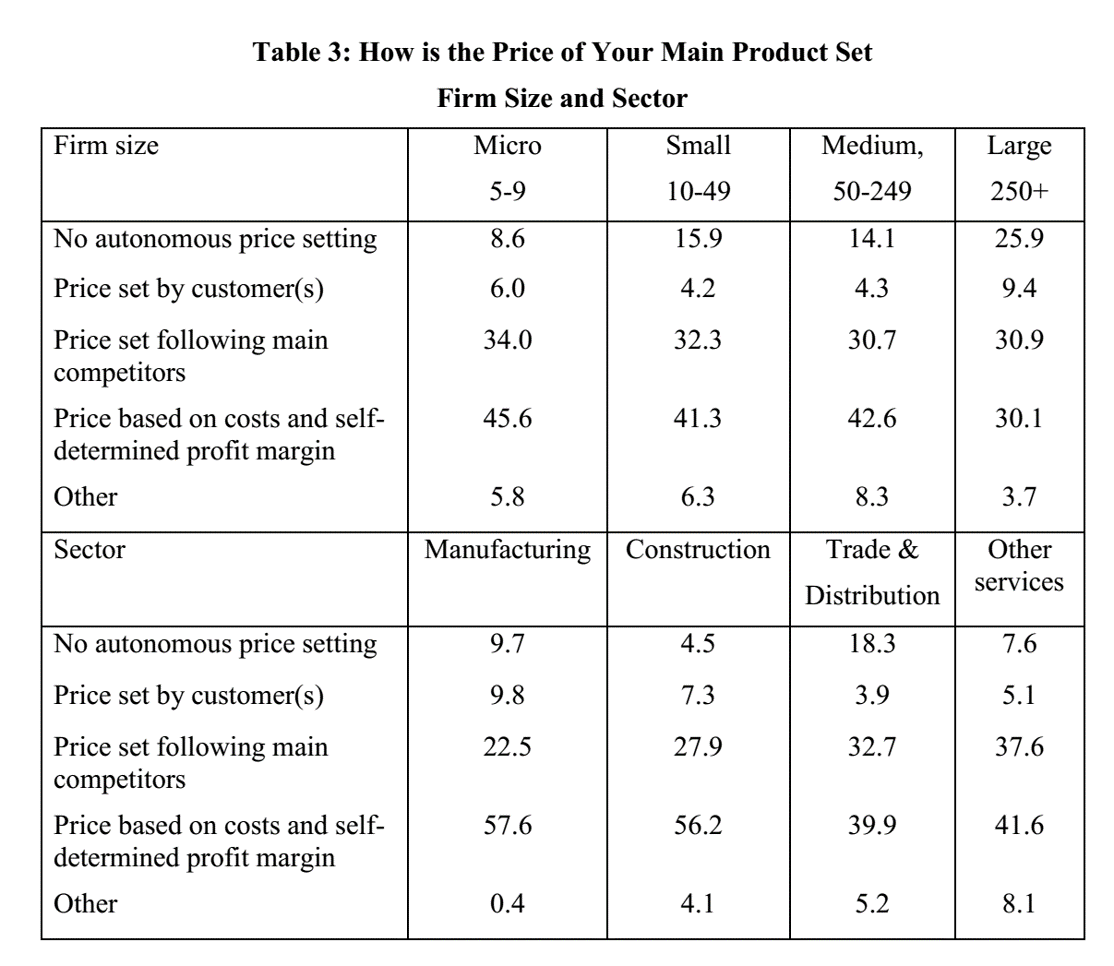
Keeney, Lawless & Murphy (2010) | 1,000 Irish businesses surveyed — how often is each approach used?
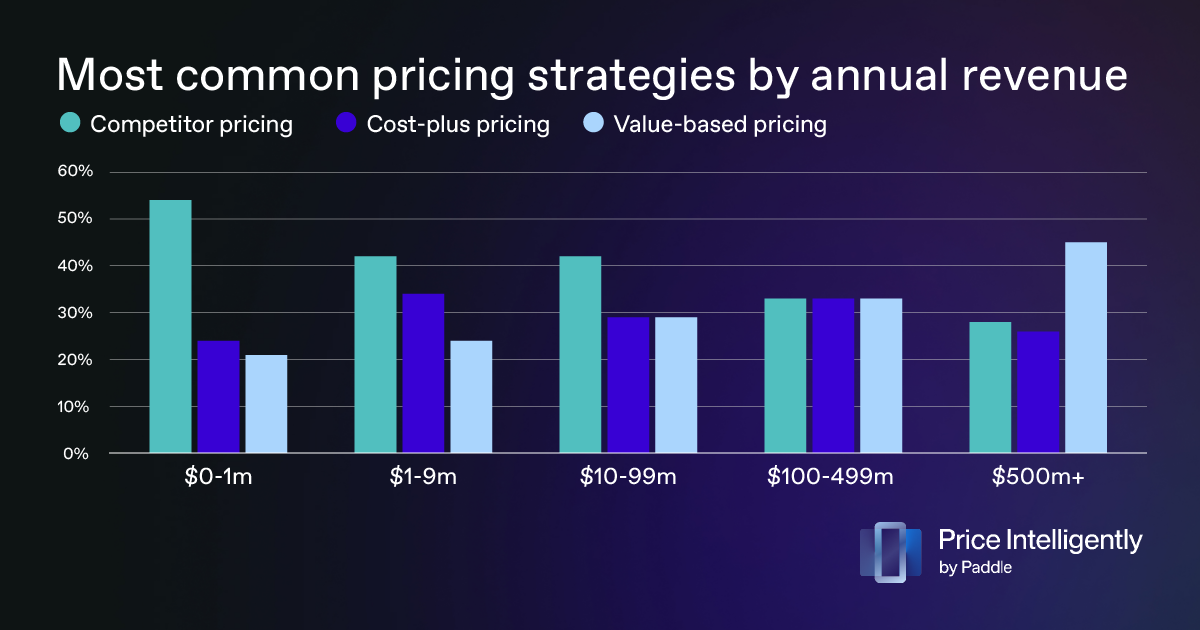
OpenView (2023) | Survey of SaaS pricing managers, by ann. rev. | Top 3 strategies so common that others are unreported
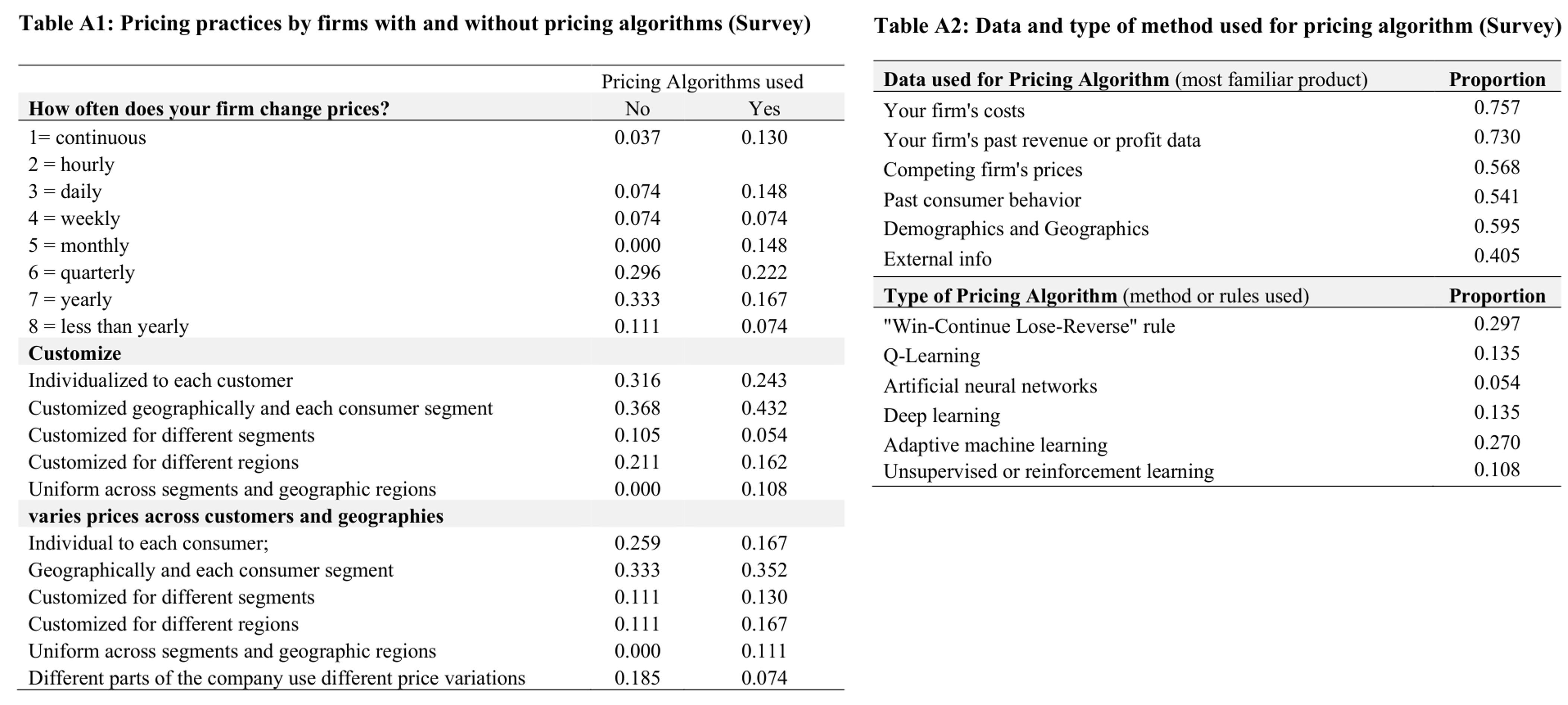
Spann et al. (2024) survey of pricing managers on EPP, a pricing/customer-growth nfp promoting algorithms
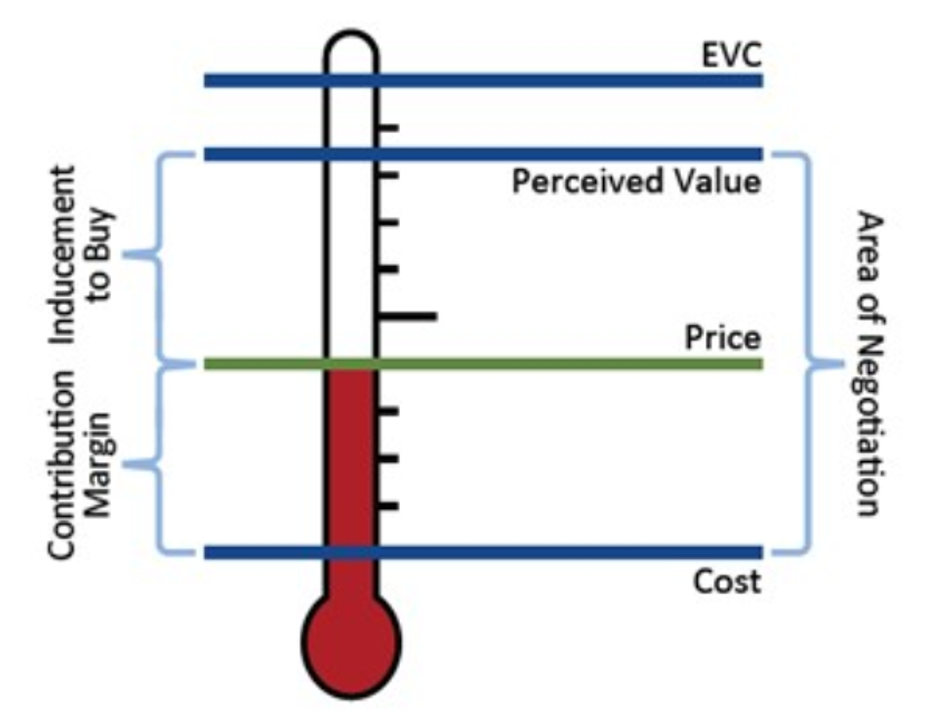
Choosing p in (Cost, EVC)
Pricing ‘Thermometer:’ How much inducement do you give your customer?
Some say: \(Price = Cost + (EVC - Cost) \cdot z\%\)
- I’ve heard z = 25%, 33%, 50%, and 70%
- Do you want profits or growth?
Human factors to consider:
- Perceived benefit - actual benefit
- Perceived costs - actual costs
- Consumer price sensitivity, reference price
- Established pricing benchmarks
- Fairness, signaling
- Customer risk of adoption, skepticism; brand credibility
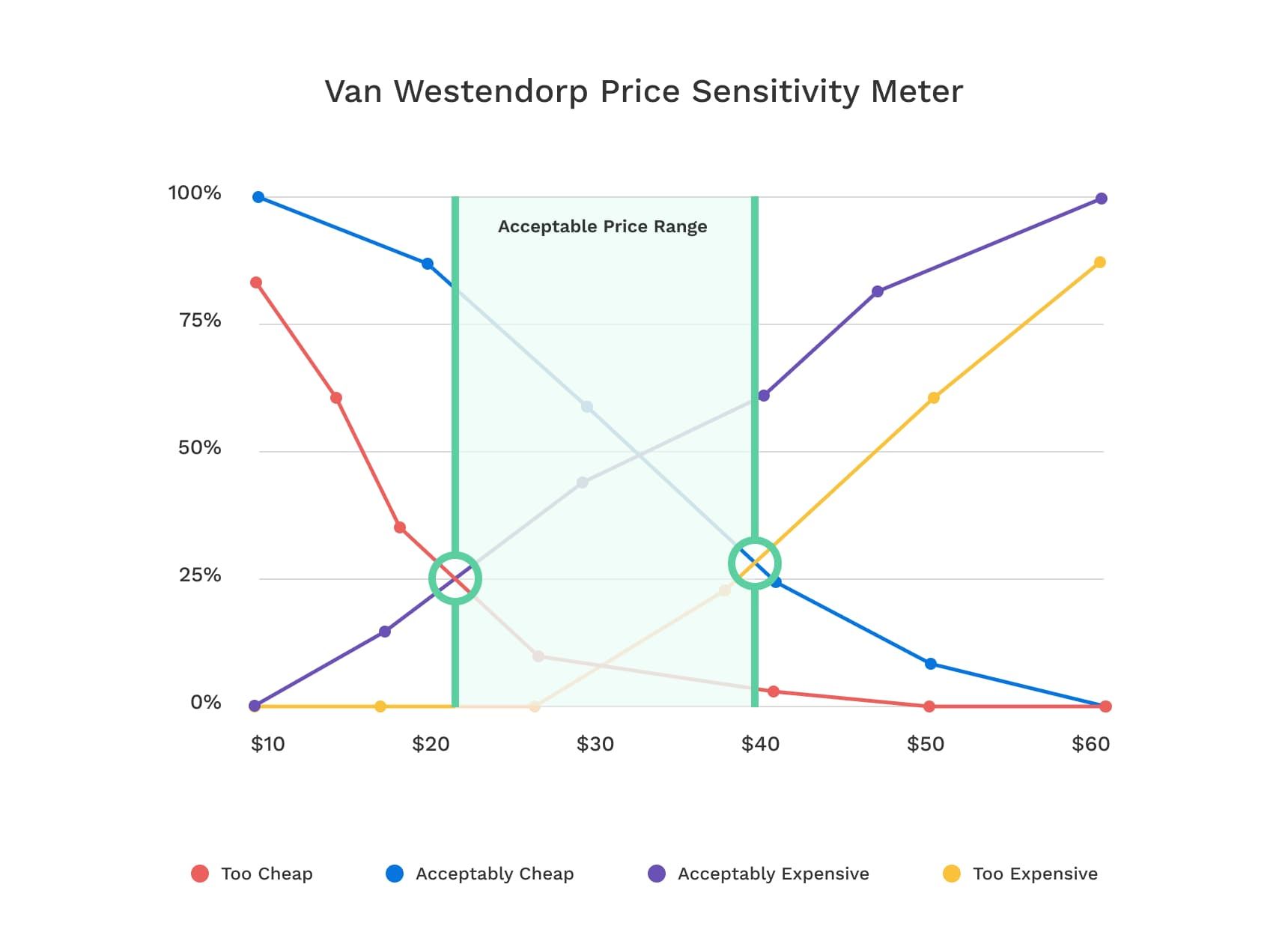
“Too Cheap” meets “Acceptably Expensive”: “Point of Marginal Cheapness”
- VW says: Price<PMC signals poor quality
“Acceptably Cheap” meets “Too Expensive”: “Point of Marginal Expensiveness”
- VW says: Price>PME prices out most of your market
“Too Cheap” meets “Too Expensive”: Possibly min. # of price-refusers
“Acceptably Cheap” meets “Acceptably Expensive”: Possibly max. # of price-accepters
These confusing ideas are largely hypothetical and not well validated
Human Factors: Price as a Signal
Human Factors: Cognitive Costs
Total customer cost is
= Cognitive cost to decide the purchase
+ Physical cost to acquire the product
+ Financial paymentSimplicity can increase sales. Remove frictions
Left-Digit Bias: Demand Effects
Left-Digit Bias: Lyft Rides
Human Factors: Price Salience
- Show the price early, late or never?
- Drinks in a loud nightclub
- USPS “Forever Stamps”
- Price advertising, coupons
- Price salience emphasizes Savings or Exclusivity

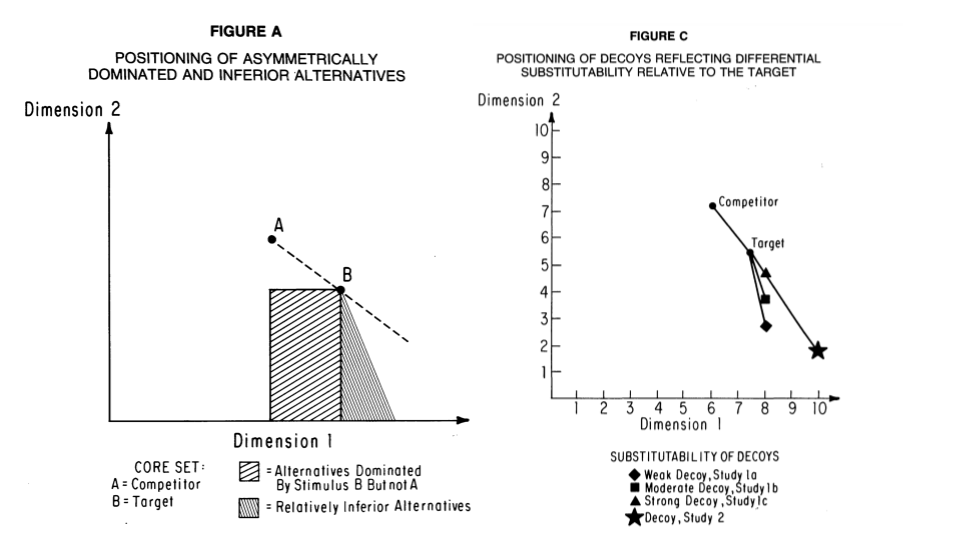
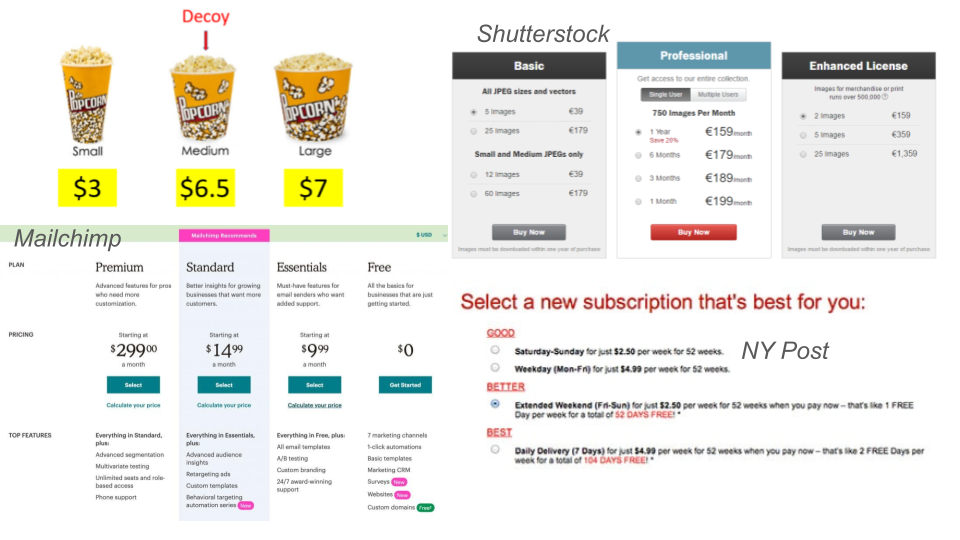
Decoy Effects
Brand A: Rated 50/100, priced at 1.80
Brand B: Rated 70/100, priced at 2.60
33% chose A
Brand A: Rated 40/100, priced at 1.60
Brand B: Rated 50/100, priced at 1.80
Brand C: Rated 70/100, priced at 2.60
47% chose B (why?)
Economic Factors: Beware a Price War!
If you explicitly mention a competitor’s price
- You make Customer aware of Competitor
- Competitor may notice: You invite them to match or retaliate
Better to price-compare vs. unnamed/generic competitor
Who wins a price war?
- Only one winner: Customer
- All firms suffer, some die
- Most likely to survive: Seller with lowest cost structure
- Smart firms avoid price wars & keep costs secret

Price Optimization: CED vs. Het. MNL
Constant Elasticity of Demand
- Assume the convenient function:
- \(q(p) = e^\alpha p^\beta\)
- This implies:
- \(\ln(q) = \alpha + \beta \ln(p)\)
- Slope coefficient is elasticity:
- \(\frac{d\ln(q)}{d\ln(p)} = \frac{p}{q}\frac{dq}{dp} = \beta\)
- You can show that maximizing \(\pi=(p-c)q(p)\) yields optimal price \(p^*\):
- \(p^* = \frac{c}{1 + \frac{1}{\beta}}\), requires \(\beta<-1\) (elastic demand)
Het. MNL Demand Model
- Estimated sales from market-share predictions at each candidate price:
- \(q(p) = M \hat{s}(p)\)
- Profit at each candidate price:
- \(\pi(p) = q(p) (p - c)\)
- Try many candidate prices, pick the one that maximizes profit:
- \(p^* = \arg\max_{\{p\}} \pi(p)\)

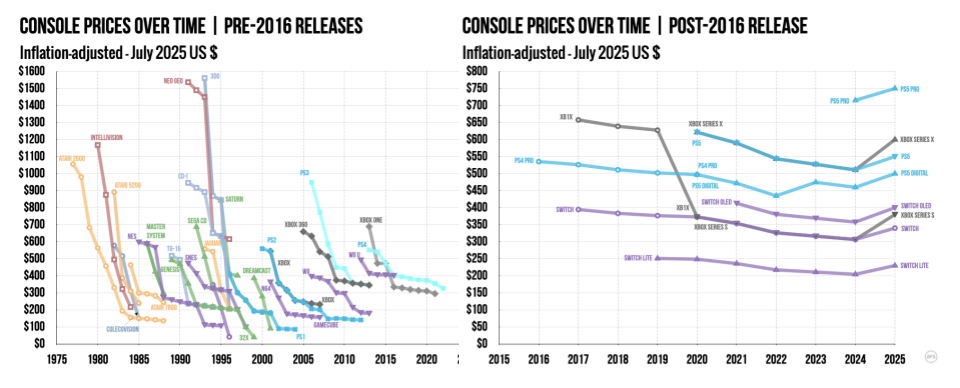
Best-Response Pricing Curve
If Firm A raises its price, some of its customers will choose to buy from Firm B. If A cuts its price, some of Firm B’s customers will choose to buy from Firm A. Either change shifts Firm B’s demand curve.
When Firm B’s demand curve shifts, Firm B’s optimal profit-maximizing price shifts in the same direction. If demand shifts up, Firm B should increase price; if demand shifts down, Firm B should decrease price.
The best-response pricing curve graphs that logic, based on Firm B’s profit-maximization calculations. It shows how Firm B’s optimal price p* changes as a function of Firm A’s price.
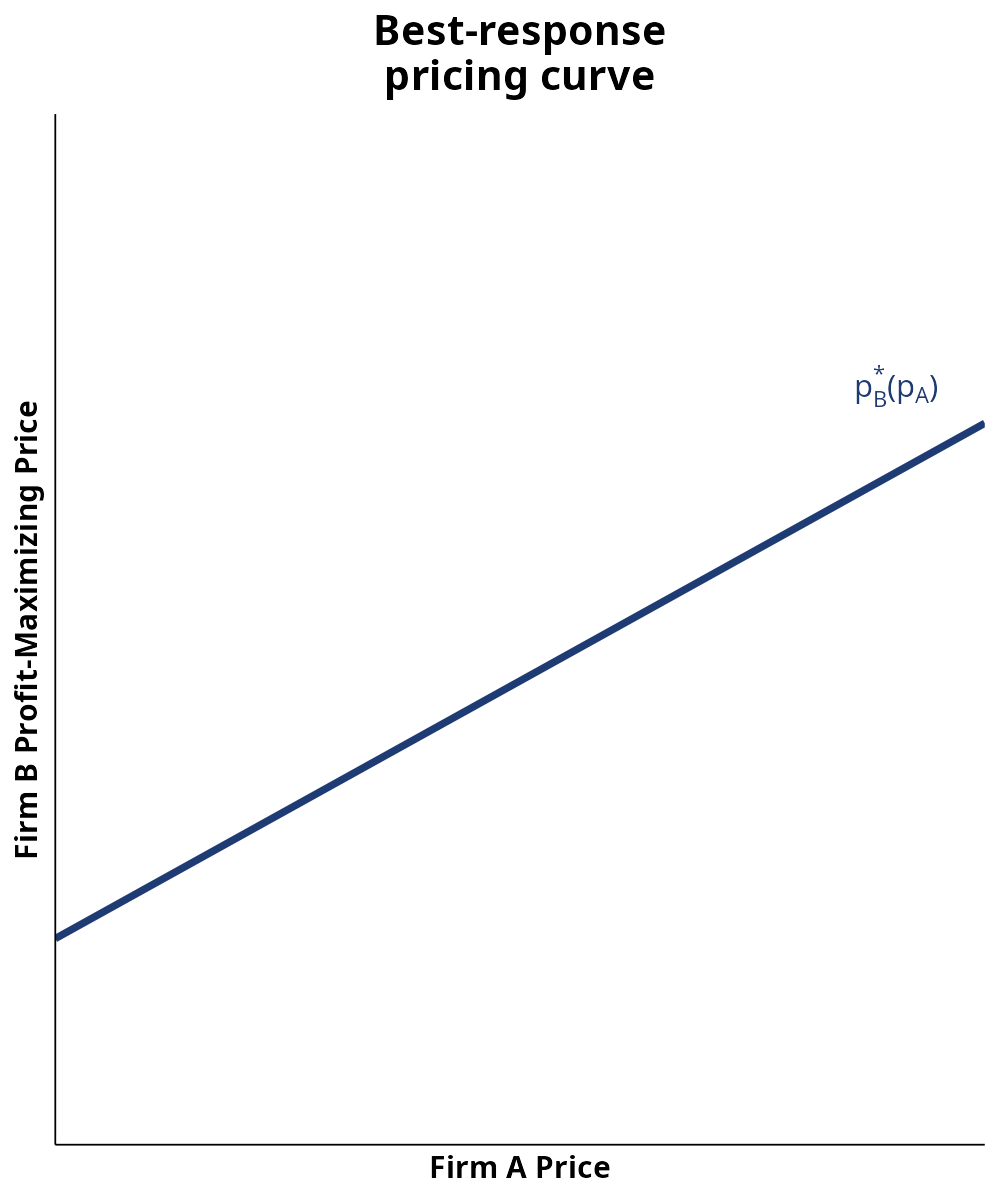
Bertrand-Nash Pricing Equilibrium
Suppose two competing firms A and B both set price to maximize profit
Then we can graph both of their best-response pricing curves as a function of the other’s observed price
The Nash equilibrium of the pricing game is given by the crossing point, where both firms are playing their best responses to the other
But what if one firm is using cost-based pricing, or competitor price benchmarking?
Class Script
Use demand model to trace out a demand curve
Compare different arc elasticity results
Conduct a grid search to find the profit-maximizing price, all else constant
Compare the grid search result to the CE-demand price
Consider multi-product price optimization
Competition
- Calculate Apple’s best-response A1 price as a function of Samsung’s S1 price
- Use the class dataset with
mdat1and the week 6 modelout10; assume Apple’s A1 marginal cost is $450 - For each S1 price in {$599, $649, $699, $749, $799, $849, $899, $949, $999}, grid-search A1 prices and find the A1 price that maximizes Apple’s A1 profit, holding all other prices fixed
- Use the class dataset with
- Plot A1’s profit-maximizing price (y-axis) against S1’s price (x-axis, using the 9 S1 price points above) — this is Apple’s best-response pricing curve

Recap
- The most common and easiest price setting methods are competitor price matching and cost-based pricing. Both are incomplete
- Consumers usually expect product prices to reflect quality positions in the marketplace
- Optimal pricing requires attention to both economic factors and human factors

Going Further
Dynamic Online Pricing with Incomplete Information Using Multiarmed Bandit Experiments
Universal Paperclips : Fun price setting game
